*For a full description, see Kaufman, Daniel & Raphael Finkel. 2018. Kratylos: A tool for sharing interlinearized and lexical data in diverse formats. Language Documentation & Conservation 12. 124-146.
To try it out, go to www.kratylos.org.
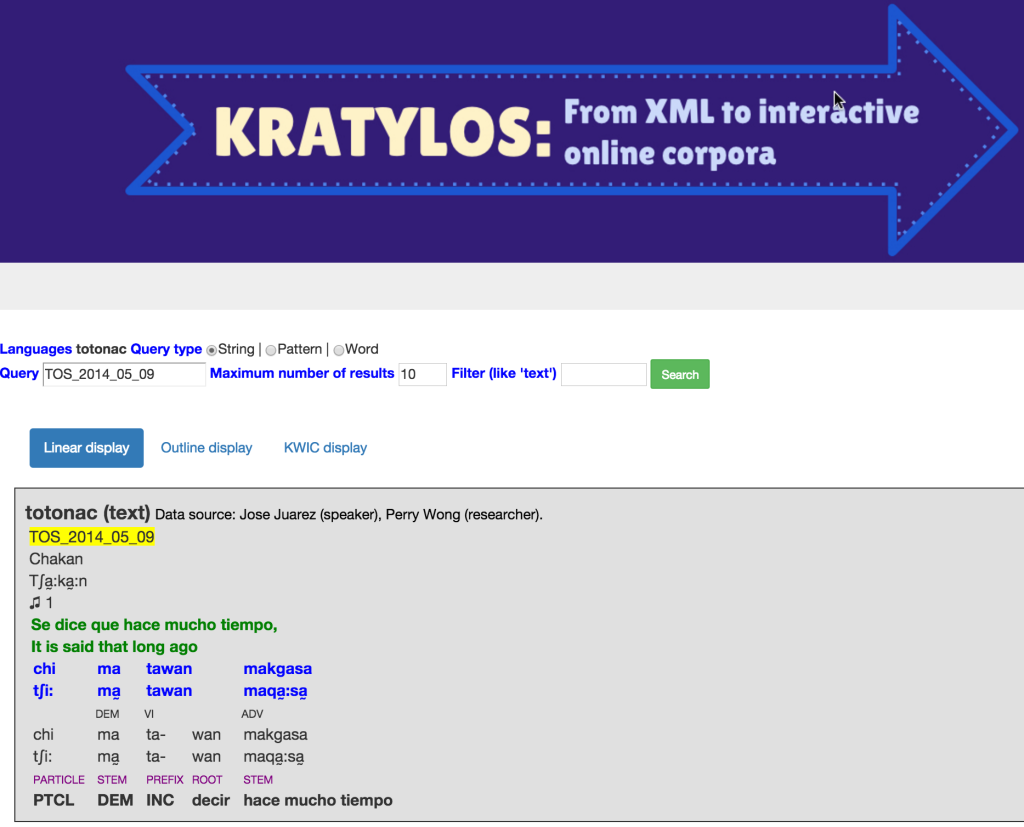
Supported by a National Science Foundation, Kratylos is a new online tool under joint development by ELA and computer scientist Raphael Finkel at the University of Kentucky. Kratylos will enable linguists to share and analyze language data more easily as well as offering new ways of collecting data online.
Today, a major gap exists in the electronic ecosystem for fieldworkers and other linguists who use software such as Toolbox and FLEx: there is still no easy method for sharing projects containing a lexicon and glossed interlinearized texts in a way that enables complex searches and the elicitation of feedback through the Internet.
Kratylos complements rather than competes with existing database software, building on the Fieldworks Language Explorer (FLEx) software developed by SIL, which has a large international and highly active user community. Kratylos effectively replicates its powerful search features for online users. With Kratylos, a FLEx project can be transformed into a linked online concordance and dictionary, complete with audio and video media — a record of a language.
Why XML?
Best practices in linguistic documentation demands the use of formats that are maximally interoperable and least likely to become obsolete. As a result, linguistic data in electronic format is increasingly being encoded in Extensible Markup Language, XML for short. XML is a format for encoding documents that can be read easily by both humans and computers. Information must be classified using start-tags and end-tags so that each part of the document belongs unambiguously to the various sections or categories that exist within the scheme. To take a simple example, what we would write informally as,
Step 1: Find A
Step 2: Find B
Step 3: Connect A to B
would be expressed as the following in XML, where each step is enclosed by a start-tag and an end-tag and the whole set of steps are embedded within a procedure, with its own start- and end-tags.
<procedure>
<step number="1">Find A.</step>
<step number="2">Find B.</step>
<step number="3">Connect A to B.</step>
</procedure>
The tags tell us unambiguously where the string begins and ends as well as informing us that it is a step. In the schema employed, steps have the attribute “number” which marks each step distinctly. There are serious benefits to storing linguistic information (lexical data and interlinearized texts) in a tagged, well-delineated, hierarchical format. The result is a human readable, unambiguous and highly interoperable code that can be used for years to come.
While XML is a great way to store linguistic data there are still no readymade solutions for displaying and searching such data. Many general programs exist for viewing XML more easily but are not particularly well suited for linguistic analysis. In addition, XML viewers are stand-alone programs that are not designed to facilitate sharing data through the internet — which is crucial for documentary linguists.
Collaborating and Crowdsourcing With Kratylos
Kratylos will offer a new way for linguists to share their data, whether in XML or other standard formats, in the form of online corpora and dictionaries. This includes transforming XML exports from FLEx into a linked, searchable online corpus (complete with multimedia files) and dictionary.
The development of Kratylos began in 2015 and will continue through 2017. The system is being with complex real-world language data from four of the ELA’s ongoing language documentation projects: Ikota, Koda, Purhepecha, and Wakhi. As data collection and analysis proceeds, the FLEx databases for each project are increasing in complexity, allowing us to test Kratylos against a wide range of linguistic issues. Making these projects freely available as easily searchable corpora and dictionaries online, we will be able to involve researchers and community members directly in the documentation process.
The fate of the world’s linguistic diversity may very well hang on our ability to take advantage of “crowdsourcing” strategies for language documentation in the coming decades. Crowdsourcing initiatives are underway for collection of audio and transcription, perhaps the most effective example being BOLD (Basic Oral Language Documentation) (Bird 2010), in which audio/video data is collected, re-spoken and then translated orally in a transcription-free workflow. While BOLD targets participants with low exposure to technology and areas that may be off the grid, there is a growing but unmet need for similar strategies aimed at technology savvy contributors. Kratylos will fill that gap by allowing the guided transcription of texts.
Stay Tuned!
Currently, Kratylos is a working prototype still under development, but already able to create online databases from a user’s uploaded FLEx, Praat or ELAN data as well as play associated audio files Within the next year or two, we hope it will be a valuable public tool, free and easy to use. Email us at info@elalliance.org for more information.
